利用马萨诸塞州波士顿郊区的房屋信息数据,使用线性回归模型训练和测试一个房价预测模型,并对模型的性能和预测能力进行测试分析。使用的编程语言是python,主要使用了pandas、matplotlib、sklearn这几个包。
导入数据
Boston房价数据下载地址,提取码:nefu
1 | import pandas as pd |
数据分析
加载数据后,不要直接急匆匆地上各种处理手段,加各种模型,先慢一点,对数据进行一个初步的了解,了解其各个特征的统计值、分布情况、与目标特征的关系,最好进行可视化,这样会看到很多意料之外的东西。
基础统计运算
统计运算用于了解某个特征的整体取值情况,它的最大最小值,平均值中位数,百分数,这些都是最简单的对一个字段进行了解的手段。
1 | # print(data.describe()) # 可以查看各个特征取值的情况,最小值,最大值,均值,方差等 |
特征观察
这里主要考虑各个特征与目标之间的关系,比如是正相关还是负相关,通常都是通过对业务的了解而来的,这里就延申出一个点,机器学习项目通常来说,对业务越了解,越容易得到好的效果,因为所谓的特征工程其实就是理解业务、深挖业务的过程。比如这个问题中的三个特征:
- RM:房间个数明显应该是与房价正相关的;
- LSTAT:低收入比例一定程度上表示着这个社区的级别,因此应该是负相关;
- PTRATIO:学生/教师比例越高,说明教育资源越紧缺,也应该是负相关;
上述这三个点,同样可以用可视化的方式来验证,事实上也应该去验证而不是只靠主观猜想,有些情况下,主观感觉与客观事实是完全相反的,这里要注意。
数据划分
为了验证模型的好坏,通常的做法是进行 cv,即交叉验证,基本思路是将数据平均划分 N 块,取其中 N-1 块训练,并对另外 1 块进行做预测,并对比预测结果与实际结果,这个过程反复 N 次直到每一块都作为验证数据使用过。
1 | from sklearn.model_selection import train_test_split |
定义评价函数
这里主要是根据问题来定义,比如分类问题用的最多的是准确率(精确率、召回率也有使用,具体看业务场景更重视什么),回归问题用 RMSE (均方误差) 等等,实际项目中会根据业务特点定义评价函数。
模型训练
1 | import time |
从结果可以看出,模型拟合效果一般,所以还需要进行模型优化。
模型调优
首先观察一下数据,特征数据的范围相差比较大,最小的在10^-3^级别,而最大的在10^2^级别,所以需要数据归一化处理。
1 | from sklearn.pipeline import make_pipeline |
从之前的训练分数上来,可以观察到数据对训练样本数据的评分比较低,即数据对训练数据的欠拟合。所以可以通过低成本的方案,即增加多项式特征看能否优化模型的性能。增加多项式特征,其实就是增加模型的复杂度。
编写创建多项式模型的函数
1 | from sklearn.preprocessing import PolynomialFeatures |
接着使用二阶多项式来拟合数据:
1 | model = polynomial_model(degree=2) |
从训练分数和测试分数都提高了,看来模型缺失得到了优化。我们可以把多项式改为三阶看一下结果,从结果可以看出出现了过拟合。
学习曲线
更好的方法是画出学习曲线,这样对模型的状态以及优化方向一目了然。
- 首先编写
utils,py
1 | import numpy as np |
- 导入
utils的plot_learing_curve,并分别绘制,一阶,二阶,三阶多项式的训练误差以及交叉验证误差的图像。
1 | from utils import plot_learning_curve |
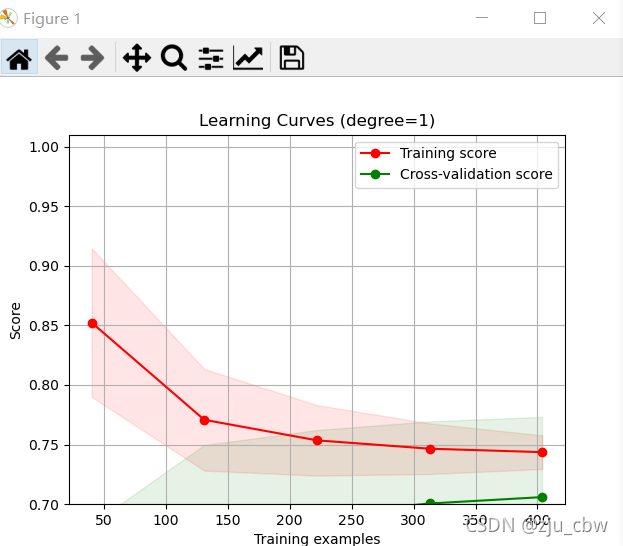
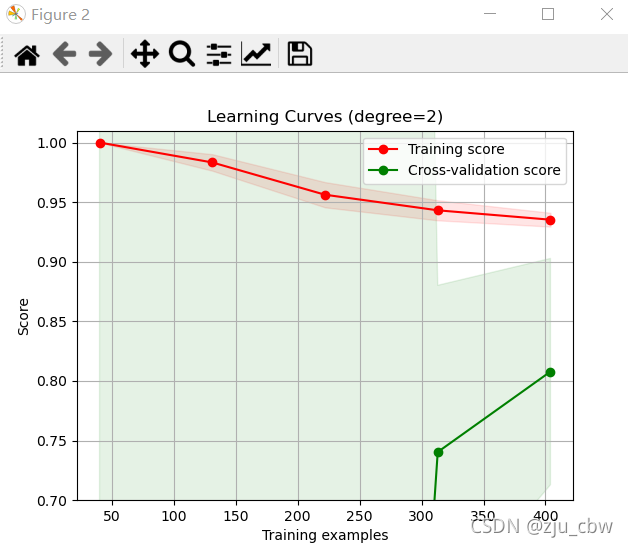
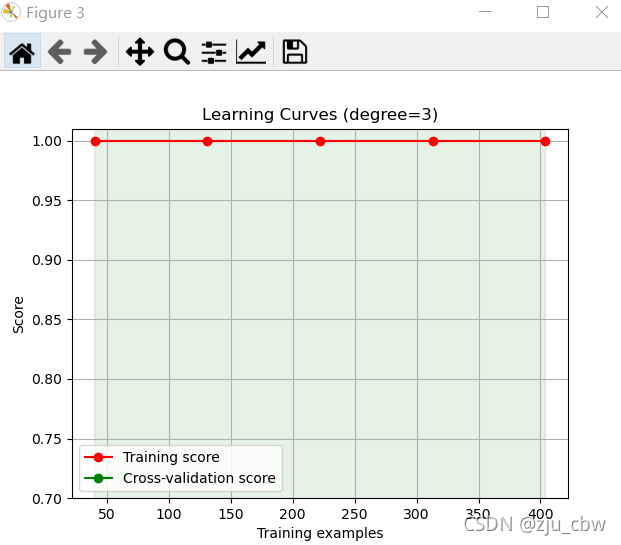
我们可以清楚的看到,一阶欠拟合,二阶是最好的,三阶过拟合。
手写版线性回归
再附一个没有用 sklearn 科学包的版本,有兴趣的可以自己研究一下。
1 | import numpy as np |