引言
我们创建一组数据,并绘出散点图。
1 | x = np.random.uniform(-3, 3, size=100) |
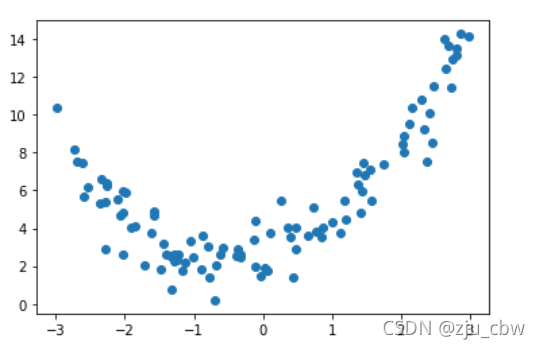
我们直接使用线性回归看看效果。
1 | from sklearn.linear_model import LinearRegression |
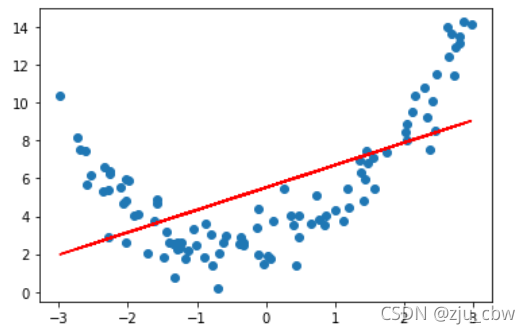
可以看出来,拟合效果不是很好,那么该如何解决呢?
多项式回归
我们试着添加一个特征,即 x的二次项,再进行线性回归。
1 | X2 = np.hstack([X, X**2]) |
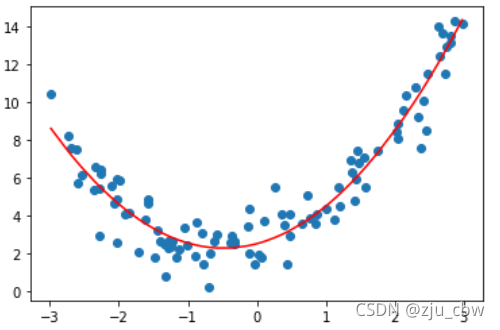
可以明显看出,拟合效果大大提高了,这就是多项式回归,利用特征的高次项,可以用来拟合非线性曲线。
sklearn包完成多项式回归
我们可以通过 sklearn 包中的 PolynomialFeatures 构建高维特征。
1 | import numpy as np |
将其升为二阶
1 | from sklearn.preprocessing import PolynomialFeatures |
其中第1项为常数项,第2第3项为一次项x1,x2,第4第6项为二次项x12,x22,第5项为x1x2。
我们再将其升为三阶看看。
1 | poly = PolynomialFeatures(degree=3) |
这十项分别对应如下:
sklearn 包没有对多项式回归进行封装,不过可以使用 Pipeline 对数据归一化、多项式生维、线性回归进行整合。代码如下:
1 | import numpy as np |
过拟合
我们可以看到,高维可以有效地拟合训练集,但有没有危害呢?我们来看看下面的情况。
我们将数据集分为训练集与测试集,分别训练一维,二维,十维,一百维。观察其在测试集上的均方误差。
一维
1 | from sklearn.model_selection import train_test_split |
输出结果:2.2199965269396573
二维
1 | from sklearn.pipeline import Pipeline |
输出结果: 0.8035641056297901
十维
1 | poly10_reg = PolynomialRegression(degree=10) |
输出结果:0.9212930722150781
我们看到二维的误差比一维小了很多,但是十维的测试误差又变大了。
百维
1 | poly100_reg = PolynomialRegression(degree=100) |
输出结果:14440175276.314638,逐渐离谱了起来。
这就是产生了过拟合的问题,即训练集表现很好,但测试集表现特别差,泛化能力很差。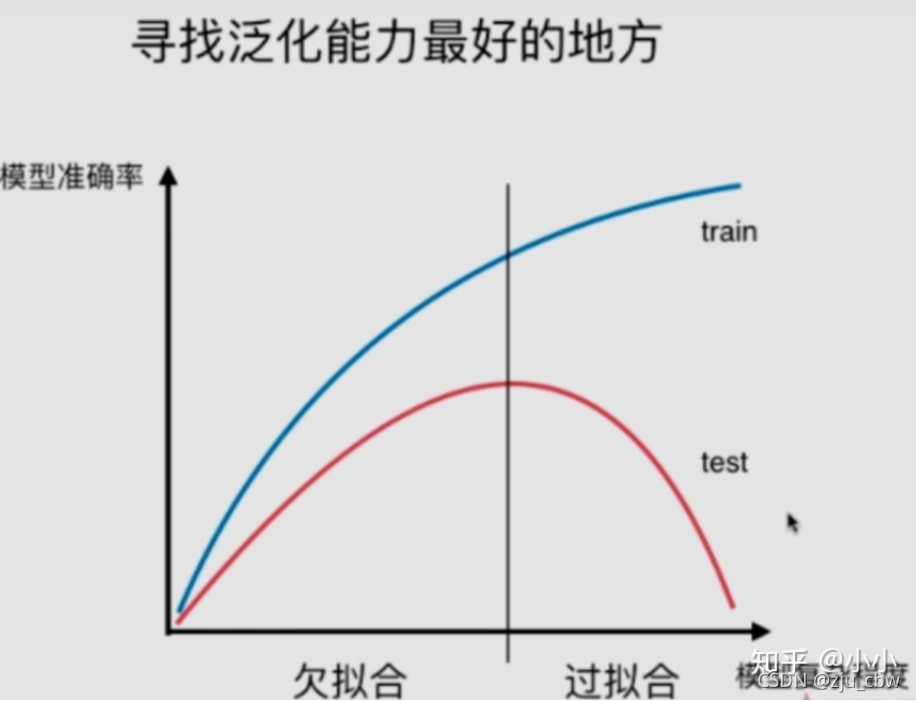
模型太简单会欠拟合,模型太复杂又会产生过拟合。那么如何辨别当前模型是欠拟合还是过拟合呢?最好的方式就是通过学习曲线判别。
学习曲线
封装一个学习曲线的函数
1 | def plot_learning_curve(algo, x_train, x_test, y_train, y_test): |
绘制一维的学习曲线
1 | plot_learning_curve(LinearRegression(), x_train, x_test, y_train, y_test) |
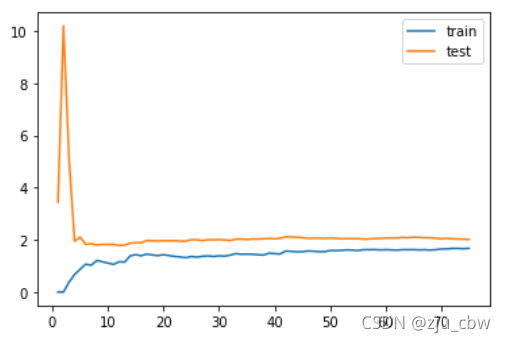
可以看出训练误差和测试误差都很大,这就是发生了欠拟合。
绘制二维的学习曲线。
1 | from sklearn.pipeline import Pipeline |
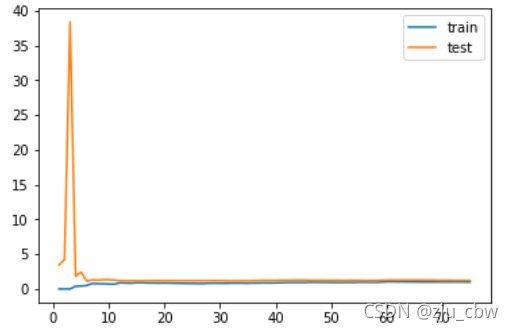
训练误差测试误差都很低,这就是最佳状态。
绘制二十维学习曲线。
1 | poly2_reg = PolynomialRegression(degree=20) |
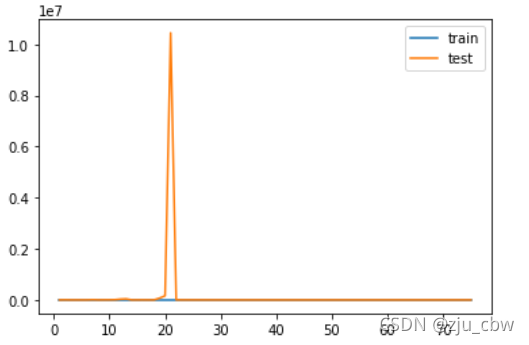
可以看出训练误差始终很低,但测试误差中间出现了很大的波动,这就是发生了过拟合。