决策树是基于树结构进行决策的。决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率。它是一种非参数学习算法,既可以解决分类问题,也可以解决回归问题。
在学习决策树前需要先对熵的概念进行了解。
信息熵
熵:用来描述事物的混乱程度,是对平均不确定性的度量。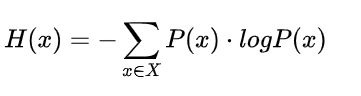
信息熵:由香农提出,。是度量样本集合纯度的最常用的指标。熵在信息论中代表随机变量不确定度的度量。一条信息大小和它的不确定性有直接关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>信息的度量就等于不确定的多少。
熵越大,数据不确定性越高,熵越低,数据的不确定性越低。假定当前样本集合D中k类样本所占比例为 pi,则信息熵的定义:
1 | import numpy as np |

基于信息熵的决策树
决策树的生成是一个递归过程,在决策树基本算法中有三种形式会导致递归结束并返回:
(1)当前结点包含所有的样本属于同一级别,无需划分;
(2)当前属性及为空,或是所有样本在所有属性上取值相同,无法划分;
(3)当前结点包含的样本集合为空,不能划分。
模拟信息熵进行划分:
1 | import numpy as np |
根据输出结果,第一次分割节点在(d=0)第一个维度的2.45处。第二次分割节点(d2=1)在第二个维度的1.75处。
基于信息熵的划分有有两种:
基尼指数
CART(Classification and Regression Tree) 决策树使用基尼指数来选择划分属性,数据集D的纯度可以使用基尼值来度量:
1 | import numpy as np |

接下来模拟gini指数进行划分:
1 | from collections import Counter |
在实际使用的过程中信息熵的计算比基尼系数稍微慢,所以 sklearn 中默认为基尼系数。对比前面的内容也能发现,大多数情况这二者并没有特别的效果优劣。
sklearn中的决策树
使用鸢尾花数据集
1 | import numpy as np |

使用基于信息熵的决策树
1 | from sklearn.tree import DecisionTreeClassifier |

使用基于基尼指数的决策树
1 | import numpy as np |

决策树解决回归问题
1 | import numpy as np |
训练分数很高,测试分数比较低,明显是发生了过拟合。
1 | param_grid = [ |
透过学习曲线了解模型过拟合情况:
1 | from sklearn.metrics import mean_squared_error |

绘制模型复杂度曲线:
1 | from sklearn.tree import DecisionTreeRegressor |

1 | maxSampleLeaf = 100 |

决策树的局限性
局限性1:横平竖直的直线划分,并不是能使用斜线。因此并不是最好的划分方式。
局限性2:对个别数据敏感。这也是非参数学习的一个共性。
1 | import numpy as np |

1 | x_new = np.delete(x, 138, axis=0) |

删除了x中的一个数据,最终的到模型就大不相同,这是因为对于非参数学习来说对于个别数据十分敏感,而且非常依赖于调参才能得到一个比较好的模型。因此一般不会单独使用决策树建立模型。