k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
Kmeans介绍
算法接受参数k,然后将事先输入的n个数据划分为k个聚类以便使得所获得的聚类满足同一聚类中的对象相似度高,而不同聚类中的相似度低。以空间中k个中心进行聚类,对最靠近他们的对象归类,通过迭代的方法,逐次更新聚类中心的值,直至得到最好的聚类结果。
- 算法描述:
(1)适当选择c个类的初始中心;
(2)在k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离更短的中心所在的类;
(3)利用均值等方法更新该类的中心值;
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,值保持不变,则迭代结束,否则继续迭代。
相似度的度量



Kmeans的计算过程

现在有4组数据,每组数据有2个维度,对其进行聚类分为2类,将其可视化一下。 A=(1,1),B=(2,1),C=(4,3),D=(5,4)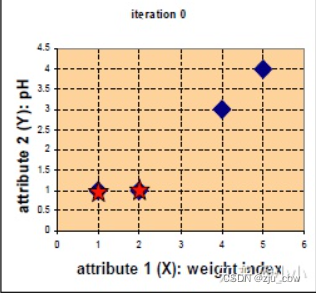
假设选取两个星的位置为初始中心 c1=(1,1),c2=(2,1) ,计算每个点到初始中心的距离,使用欧式距离得到4个点分别距离两个初始中心的距离,归于最近的类:
通过比较,将其进行归类。并使用平均法更新中心位置。
由于归于group1的只有一个点,一次更新后的中心位置 c1=(1,1),而 c2=(11/3, 8/3)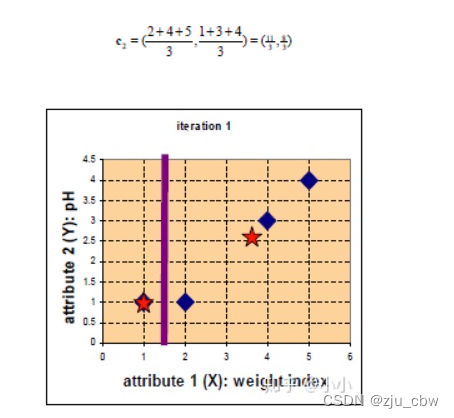
再次计算每个点与更新后的位置中心的距离
继续迭代下去,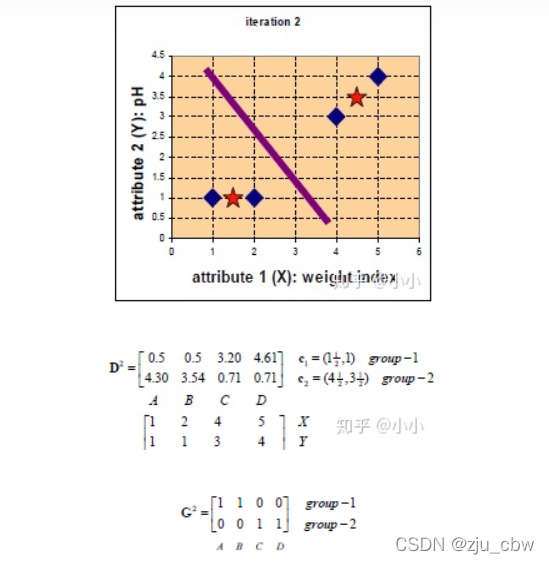
此时,与上一次的类别标记无变化,即可停止。
Kmeans的编程实现
1 | import numpy as np |
sklearn包的Kmeans聚类
1 | from sklearn.cluster import KMeans |
参数
1 | n_clusters: |
实例
首先我们随机创建一些二维数据作为训练集,观察在不同的k值下聚类算法的区别
1 | import numpy as np |
利用KMeans函数新建一个聚类算法,这里设置为2分类
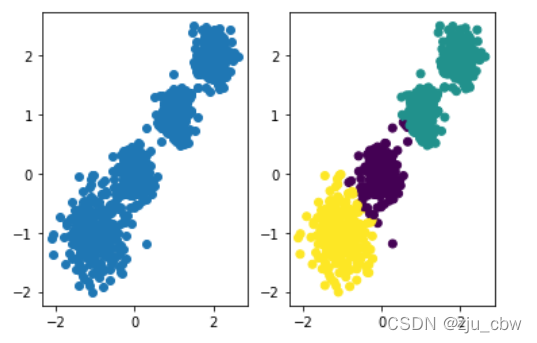
1 | y_pred = KMeans(n_clusters=2, random_state=9) |
然后进行分类
1 | y_pred = y_pred.fit_predict(X) |
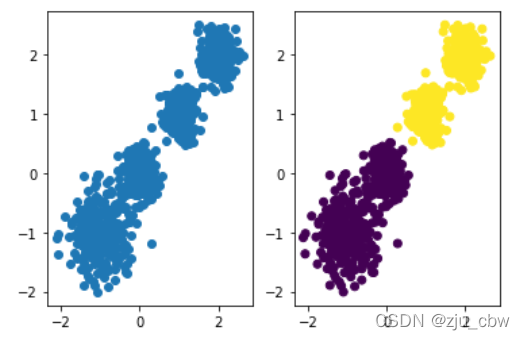
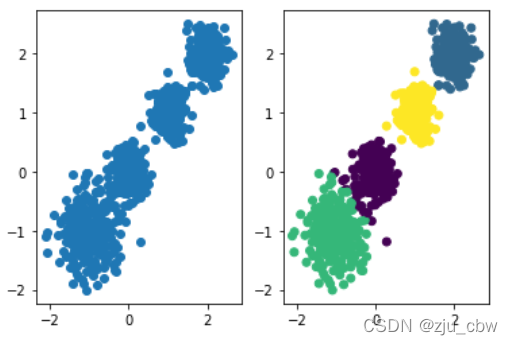
当然3分类,4分类我们只需要修改一下KMeans函数中的n_clusters参数即可
1 | y_pred = KMeans(n_clusters=3, random_state=9) |