人工神经网络(artificial neural network,ANN),简称神经网络(neural network,NN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。
神经网络概述

神经网络是一种运算模型,由大量的节点(或称“神经元”)和之间相互的联接构成。每个节点代表一种特定的输出函数,称为激励函数、激活函数(activation function)。每两个节点间的联接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
对于上面的神经网络我们需要估计以下参数:
(w11,w12,w21,w22,w1,w2,b1,b2,b3)
目标函数为:
Minimize: E(W,b) = 1/2(y-Y)2
参数估计

我们先以简单的神经网络为例。
要求九个偏导数
虽然我们可以逐一的计算这些偏导数,但是这样做的计算量太大,我们其实可以利用神经网络这种分层结构,来简化求解偏导数的计算,这个算法也被称为后向传播算法。
可以用已经算出的偏导数去计算还没有算出的另一些偏导数,这比直接计算9个偏导数要方便很多。
在这个网络中先计算Z1,Z2,y的偏导数。因为这三个点是整个网络的枢纽,其他偏导数都可以很容易地通过这三个点的偏导数算出来,接下来我们来计算这三个偏导数。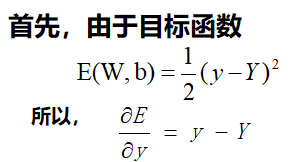




通过这三个关键位置的偏导数,很容易求出前面9个偏导数。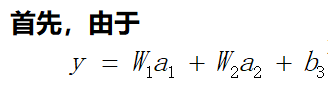

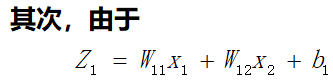





后向传播
人工神经网络后向传播算法的步骤:

更一般的神经网络
之前我们是通过简单的神经网络模型来推到后向传播的,下面我们通过更一般的神经网络进行后向传播。










一般情况下,反向传播算法的算法流程:




神经网络的改进
对非线性(激活函数)的改进

如果使用阶跃函数,导数就不是连续的了,所以我们对其进行改进,有以下几种选择。
- sigmoid函数
这个我们在逻辑回归中使用过。


双曲正切tanh函数


ReLU函数



Leaky Relu函数

Maxout函数

如何选择非线性函数作为激活函数
目标函数










随机梯度下降法(SGD)





鸢尾花分类
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
- 属性:
Sepal.Length(花萼长度),单位是cm;
Sepal.Width(花萼宽度),单位是cm;
Petal.Length(花瓣长度),单位是cm;
Petal.Width(花瓣宽度),单位是cm; - 种类:
Iris Setosa(山鸢尾)(本例中使用数字‘0’表示)
Iris Versicolour(杂色鸢尾)(本例中使用数字‘1’表示)
Iris Virginica(维吉尼亚鸢尾)(本例中使用数字‘2’表示)
- 定义sigmoid函数
1 | # define sigmoid function |
神经网络结构确定
该函数主要是为了获取输入量x的矩阵大小,以及标签y的矩阵大小。1
2
3
4
5
6
7
8
9
10
11
12def layer_size(X, Y):
"""
:param X: input dataset of shape (input size, number of examples) (输入数据集大小(几个属性,样本量))
:param Y: labels of shape (output size, number of exmaples) (标签数据大小(标签数,样本量))
:return:
n_x: the size of the input layer
n_y: the size of the output layer
"""
n_x = X.shape[0]
n_y = Y.shape[0]
return (n_x, n_y)权重和偏移量参数初始化
该函数主要是为了初始化我们的连接权重w和偏移量b。要注意的是确保参数矩阵大小正确。
1 | def initialize_parameters(n_x, n_h, n_y): |
正向传播计算
该函数为正向传播计算,需要注意的是,中间层的激活函数为tanh,输出层的激活函数为sigmoid。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31def forward_propagation(X, parameters):
"""
forward_propagation
(正向传播)
:param X: input data of size (n_x, m) (输入数据集X)
:param parameters: python dictionary containing your parameters (output of initialization function) (字典类型,权重以及偏移量参数)
:return:
A2: The sigmoid output of the second activation (第2层激活函数sigmoid函数输出向量)
cache: a dictionary containing "Z1", "A1", "Z2" and "A2" (字典类型,包含"Z1", "A1", "Z2", "A2")
"""
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1) #第1层激活函数选择tanh
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2) #第2层激活函数选择sigmod
assert (A2.shape == (1, X.shape[1])) #若A2的大小和((1, X.shape[1]))不同,则直接报异常
cache = {
'Z1': Z1,
'A1': A1,
'Z2': Z2,
'A2': A2,
}
return A2, cache代价函数计算
该函数主要是为了计算代价函数,注意一个样本的期望输出和实际输出的误差的平方用来定义损失函数,在向量化的计算过程中,这里使用了代价函数。
交叉熵损失是分类任务中的常用损失函数,最后一层是sigmoid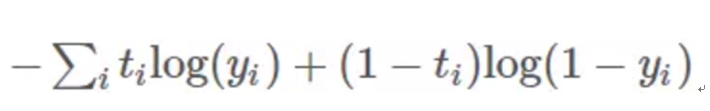
1 | def compute_cost(A2, Y, parameters): |
- 反向传播计算
该函数为方向传播计算。
1 | def backward_propagation(parameters, cache, X, Y): |
- 权重和偏移量参数更新
该函数为更新权重和偏移量参数。
1 | def update_parameters(parameters, grads, learning_rate): |
- BP神经网络
我们将上面的几个函数组合起来,就可以得到一个两层的BP神经网络模型。
1 | def nn_model(X, Y, n_h, num_iterations, learning_rate, print_cost=False): |
- 鸢尾花分类测试
1 | import numpy as np |
测试结果
测试中,将150个数划分成了90个训练数据,60个测试数据。神经网络的中间层为10个神经元,迭代次数为10000次,学习率为0.25。在训练和测试中,需要对数据进行归一化,其中包括对标签数据Y的归一化。
设置的三类鸢尾花的标签分别是0,1,2。通过归一化之后,获得的标签数据为0,0.5,1。对测试集获得的结果,进行归档,小于0.2的为0,大于0.8的为1,其余的均为0.5。
最终获得的分类结果的准确率是多少。

sklearn包神经网络的使用可以看这篇博客。