LeNet神经网络介绍
LeNet神经网络由深度学习三巨头之一的Yan LeCun提出,他同时也是卷积神经网络 (CNN,Convolutional Neural Networks)之父。LeNet主要用来进行手写字符的识别与分类,并在美国的银行中投入了使用。LeNet的实现确立了CNN的结构,现在神经网络中的许多内容在LeNet的网络结构中都能看到,例如卷积层,Pooling层,ReLU层。虽然LeNet早在20世纪90年代就已经提出了,但由于当时缺乏大规模的训练数据,计算机硬件的性能也较低,因此LeNet神经网络在处理复杂问题时效果并不理想。虽然LeNet网络结构比较简单,但是刚好适合神经网络的入门学习。
LeNet神经网络结构
LeNet的神经网络结构图如下: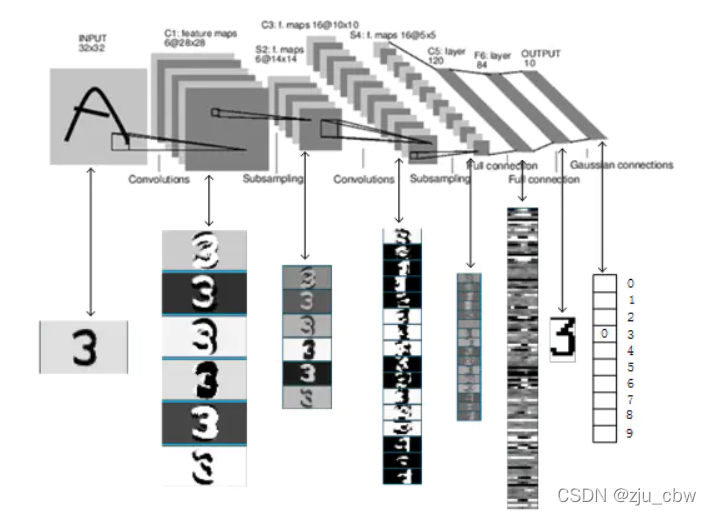
LeNet网络的执行流程图如下: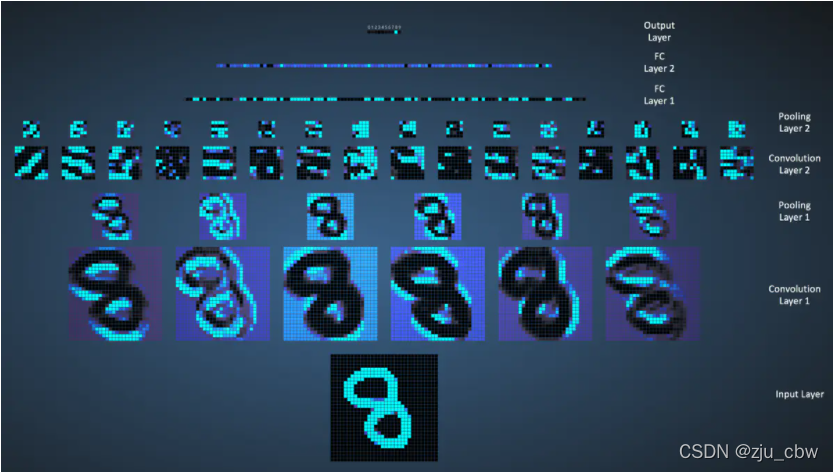
LeNet各层的参数变化
C1
输入大小:32*32
核大小:5*5
核数目:6
输出大小:28*28*6
训练参数数目:(5*5+1)*6=156
连接数:(5*5+1)*6*(32-2-2)*(32-2-2)=122304S2
输入大小:28*28*6
核大小:2*2
核数目:1
输出大小:14*14*6
训练参数数目:2*6=12,2=(w,b)
连接数:(2*2+1)*1*14*14*6 = 5880C3
输入大小:14*14*6
核大小:5*5
核数目:16
输出大小:10*10*16
训练参数数目:6*(3*5*5+1) + 6*(4*5*5+1) + 3*(4*5*5+1) + 1*(6*5*5+1)=1516
连接数:(6*(3*5*5+1) + 6*(4*5*5+1) + 3*(4*5*5+1) + 1*(6*5*5+1))*10*10=151600S4
输入大小:10*10*16
核大小:2*2
核数目:1
输出大小:5*5*16
训练参数数目:2*16=32
连接数:(2*2+1)*1*5*5*16=2000C5
输入大小:5*5*16
核大小:5*5
核数目:120
输出大小:120*1*1
训练参数数目:(5*5*16+1)*120*1*1=48120(因为是全连接)
连接数:(5*5*16+1)*120*1*1=48120F6
输入大小:120
输出大小:84
训练参数数目:(120+1)*84=10164
连接数:(120+1)*84=10164
LeNet第三层(卷积操作)
值得关注的是LeNet第三层,LeNet第三层(C3层)也是卷积层,卷积核大小仍为5*5,不过卷积核的数量变为16个。第三层的输入为14*14的6个feature map,卷积核大小为5*5,因此卷积之后输出的feature map大小为10*10,由于卷积核有16个,因此希望输出的feature map也为16个,但由于输入有6个feature map,因此需要进行额外的处理。输入的6个feature map与输出的16个feature map的关系图如下: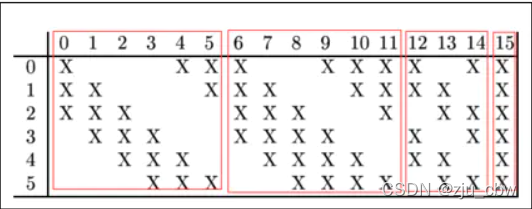
如上图所示,第一个卷积核处理前三幅输入的feature map,得出一个新的feature map。
LetNet(Pytorch版本)
model.py
1 | import torch.nn as nn |

train.py
1 | #train.py |