这篇文章主要讲述用 pytorch 完成简单 CNN 图片分类任务,如果想对 CNN 的理论知识进行了解,可以看我的这篇文章,深度学习(一)——CNN卷积神经网络。
图片分类
我们以美食图片分类为例,有testing、training、validation文件夹。下载链接放下面。
点击提取, 提取码:nefu
前面的 0 表示其为 0 类,后面为其编号。
这篇文章主要讲述用 pytorch 完成简单 CNN 图片分类任务,如果想对 CNN 的理论知识进行了解,可以看我的这篇文章,深度学习(一)——CNN卷积神经网络。
我们以美食图片分类为例,有testing、training、validation文件夹。下载链接放下面。
点击提取, 提取码:nefu
前面的 0 表示其为 0 类,后面为其编号。
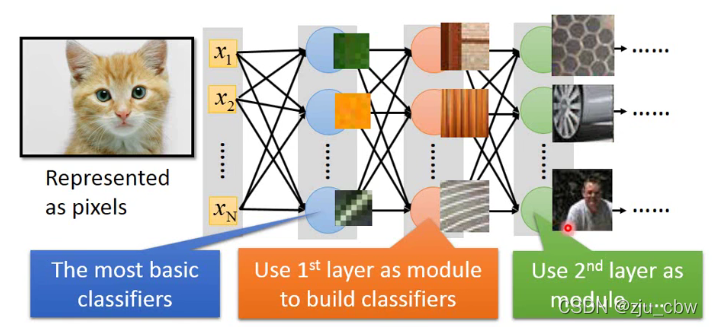
人工神经网络(artificial neural network,ANN),简称神经网络(neural network,NN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。根据个体学习器的生成方式,目前集成学习的方法大致分为两类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法;另一类就是个体学习器之间不存在强依赖关系、可同时生成的并行化方法。前者的代表是Boosting,后者的代表室Bagging和随机森林。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行广义线性分类,其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。SVM可以通过核函数进行非线性分类,是常见的核学习(kernel learning)方法之一。
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
决策树是基于树结构进行决策的。决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率。它是一种非参数学习算法,既可以解决分类问题,也可以解决回归问题。
在学习决策树前需要先对熵的概念进行了解。
如果现在有一个癌症预测系统,输入患者的信息,可以判断是否有癌症。如果只使用分类准确度来评价模型的好坏是否合理?假如此时模型的预测准确度是99.9%,那么是否能认为模型是好的呢?如果癌症产生的概率只有0.1%,那就意味着这个癌症预测系统只有预测所有人都是健康,即可达到99.9%的准确率。那么此时还认为模型是好的嘛?假如更加极端一点,如果癌症产生的概率只有0.01%,那就意味着这个癌症预测系统只有预测所有人都是健康,即可达到99.99%的准确率。到这里,就能大概理解分类准确度评价模型存在的问题。什么时候才会出现这样的问题呢?这就是对于极度偏斜的数据(Skewed Data),也就样本数据极度不平衡的情况下,只使用分类准确度是远远不够的。因此需要引进更多的指标。
首先使用混淆矩阵(Confusion Matrix) 做进一步的分析。首先针对二分类问题,进行混淆矩阵分析。我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是 positive,哪些结果是 negative。
逻辑回归(Logistics Regression),逻辑回归虽然叫回归,但实际上属于分类算法,常用于二分类的任务。当然逻辑回归也可以用于多分类,这就需要加上其它的方法。至于逻辑回归是怎么解决分类问题,实质上是把样本特征和样本发生的概率联系起来。